Notes for Introduction to Machine Learning in Production (MLOps1) on Coursera/Deeplearning.ai
Week 1: Steps of an ML project
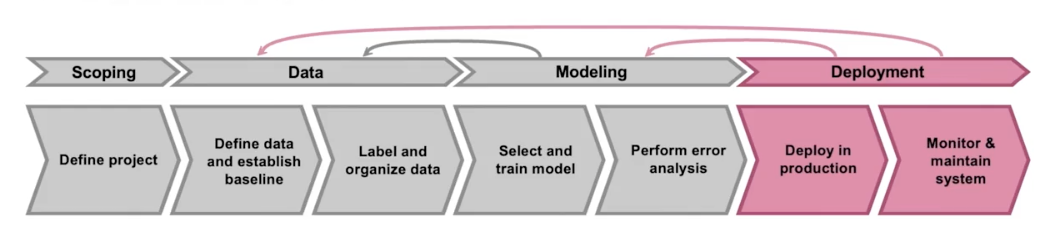
The ML project lifecycle
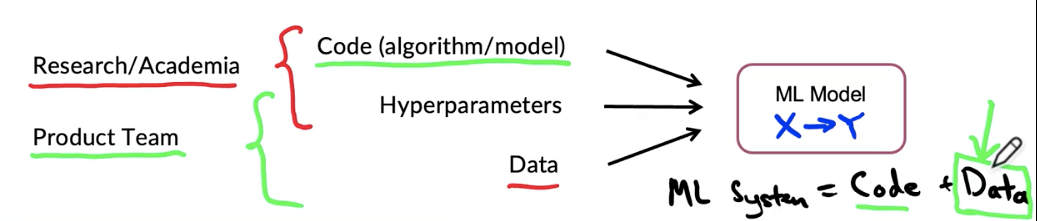
MLOps (Machine learning Operations) comprises a set of tools and principles to support progress through the ML project lifcycle.
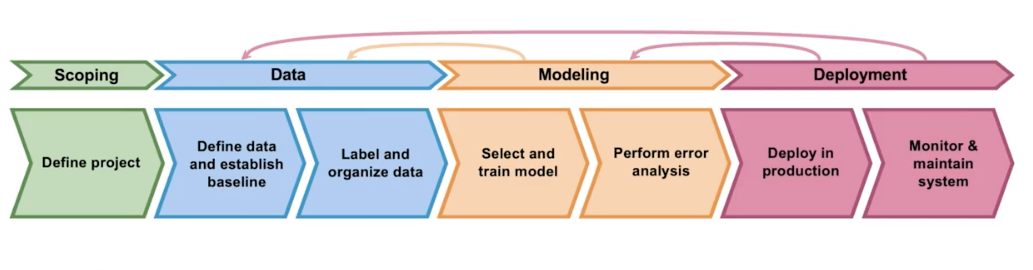
Scoping
- Decide to work on speech recognition for voice search
- Decide on key metrics:
- Acc, latency, throughput
- Estimate resources and timeline
Define data
- Is the data labeled consistently
- How much silence before/after each clip?
- How to perform volume normalization?
Modeling
Deployment
Data drift and concept drift
Data drift: the input data has changed. The distribution of the variables is meaningfully different. As a result, the trained model is not relevant for this new data.
Concept drift occurs when the patterns the model learned no longer hold.
In contrast to the data drift, the distributions (such as user demographics, frequency of words, etc.) might even remain the same. Instead, the relationships between the model inputs and outputs change.
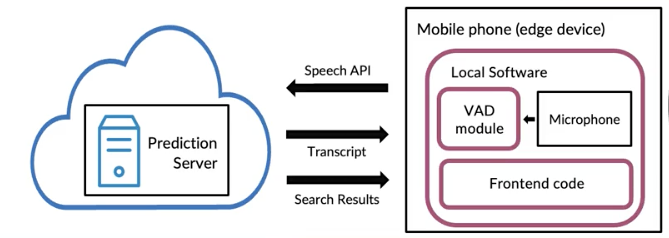
Software engineering issues
- Realtime of Batch
- Cloud vs. Edge/Browser
- Compute resources (CPU/GPU/memory)
- Latency, throughput (QPS)
- Logging
- Security and privacy
Common deployment cases
- New product/capability
- Automate/assist with manual task
- Replace previous ML system
Key idesa:
- Gradual ramp up with monitoring
- Rollback
Shadow mode
- ML system shadows the human and runs in parallel.
- Ml system’s output not used for any decisions during this phase.
Canary deployment
- Roll out to small fraction (say 5%) of traffic initially.
- Monitor system and ramp up traffic gradually.
Blue green deployment
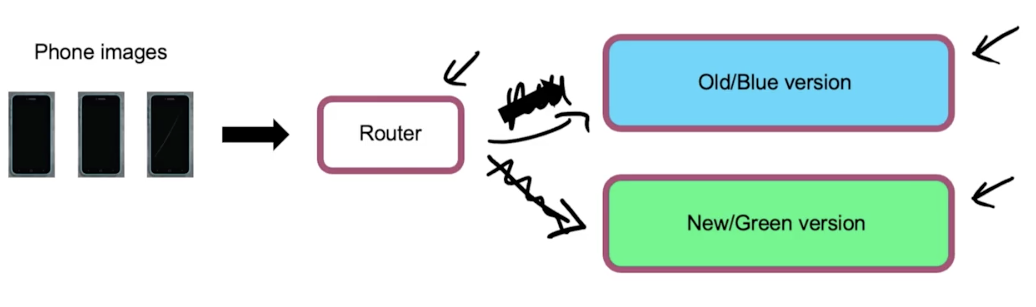
- Easy way to enable rollback
Degrees of automation
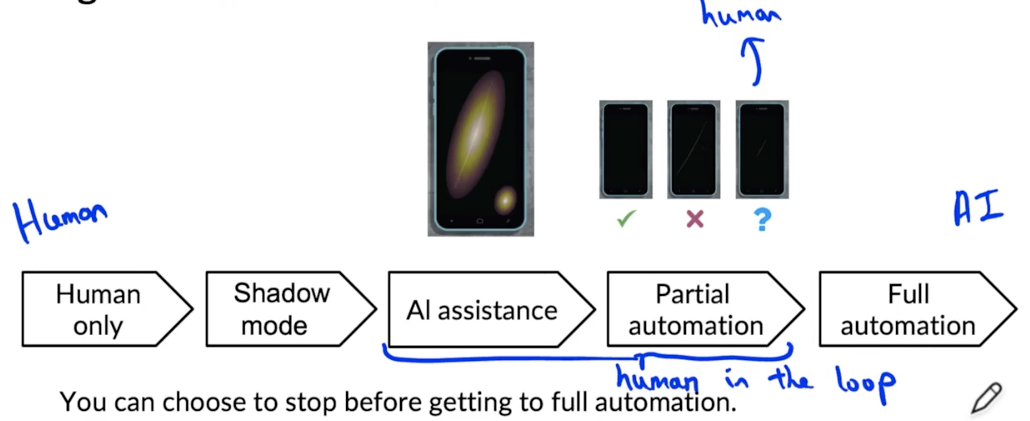
Monitoring dashboard
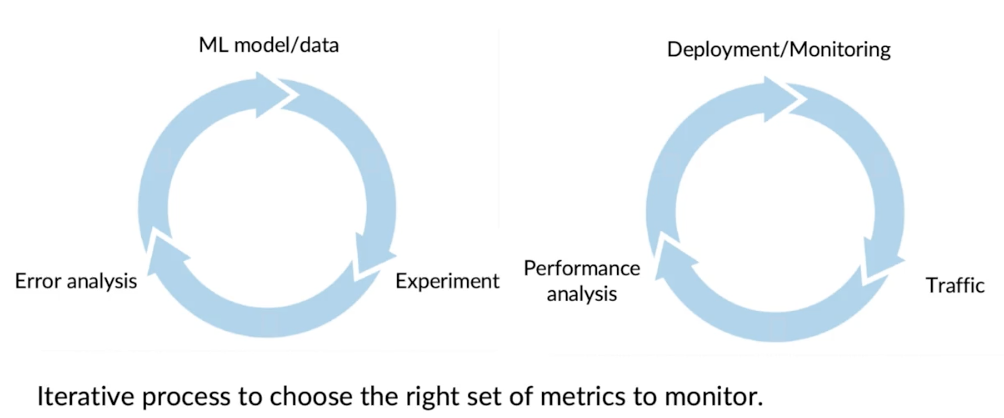
- Brainstorm the things that could go wrong.
- Brainstorm a few statistics/metrics that will detect the problem.
- It is ok to use many metrics initially and gradually remove the ones you find not useful.
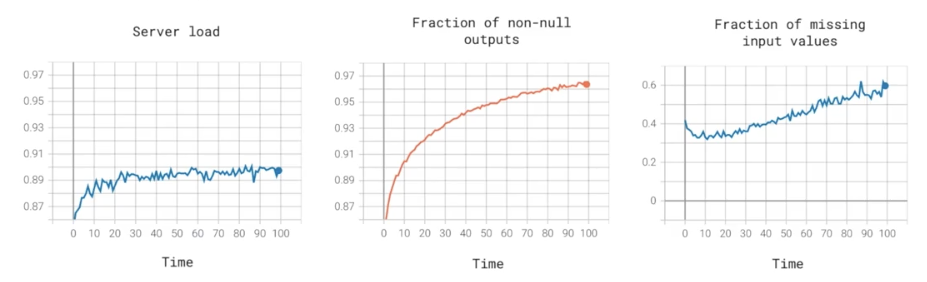
Examples of metrics to track
- Software metrics: memory, compute, latency, throughout, server load
- Input metrics: avg input length, avg input volume, num missing values, avg image brightness
- Output metrics # times return ‘'(null), # times user
Just as ML modeling is iterative, so is deployment
Monitoring dashboard
- Set thresholds for alarms
- Adapt metrics and thresholds over time
Model maintenance
- Manual retraining
- Automatic retraining
Metrics to monitor
- Monitor
- Software metrics
- Input metrics
- Output metrics
- How quickly do they change?
- User data generally has slower drift.
- enterprise data (B2B applications) can shift fast.
Code Link : Github Repo
Reading Material Week 1:
- Machine Learning in Production: Why You Should Care About Data and Concept Drift
- Monitoring Machine Learning Models in Production
- A Chat with Andrew on MLOps: From Model-centric to Data-centric AI
Week 2: Select and train model
Selecting and Training a Model
Model development is an iterative process
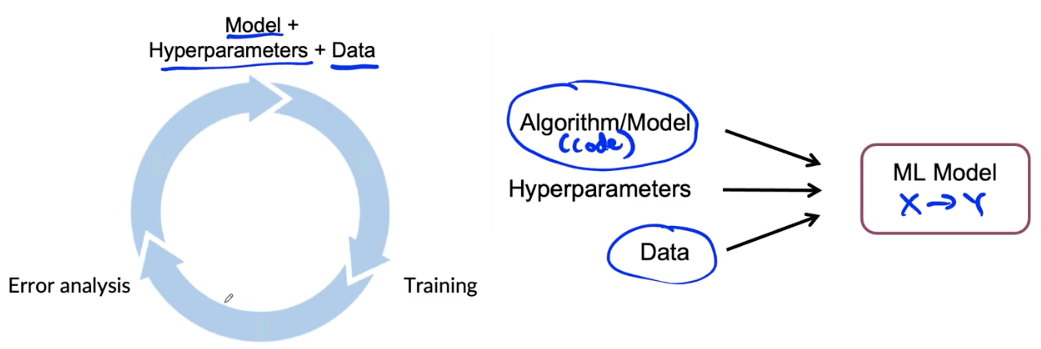
Challenges in model development
- Doing well on training set (usually measured by average training error)
- Doing well on dev/test sets.
- Doing well on business metrics/project goals.
Performance on disproportionately important example
Web search example
- Informational and transactional queries
- Navigational queries
Performance on key slices of the dataset
- Example: ML for loan approval: makes sure not to discriminate by ethnicity, gender, location, language of other protected attributes.
- Example: Product recommendations from retailers: Be careful to treat fairly all major user, retailer, and product categories.
Rare classes
- Skewed data distribution
- Accuracy in rare classes
Unfortunate conversation in many companies
- I did well on the test set
- But this doesn’t work for my application
Establishing a baseline level of performance
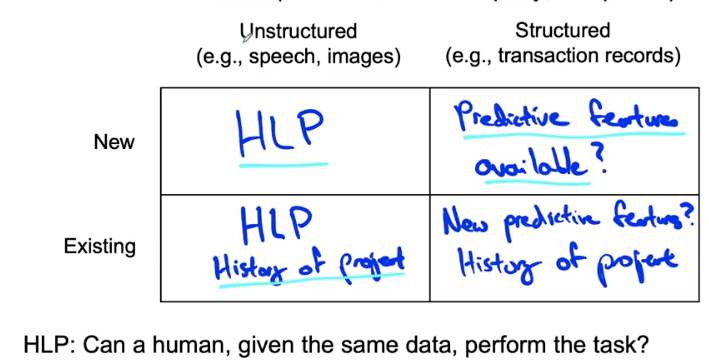
Unstructured and structured data
- Unstructured data: Image, Audio, Text (HLP is important)
- Structured data: a data frame
Ways to establish a baseline
- Human level performance
- Literature search for state-of-the-art/open source
- Quick-and-dirty implementation
- Performance of older system
Baseline helps to indicates what might be possible. In some cases (such as HLP) is also gives a sense of what is irreducible error/Bayes error.
Getting started on modeling
- Literature search to see what’s possible (courses, blogs, open-source projects).
- Find open-source implementations if available.
- A reasonable algorithm with good data will often outperform a great algorithm with no so good data.
Deployment constraints when picking a model
Should you take into account deployment constraints when picking a model?
- Yes, if baseline is already established and goal is to build and deploy.
- No (or not necessarily), if purpose is to establish a baseline and determine what is possible and might be worth pursuing.
Sanity-check for code and algorithm
- Try to overfit a small training dataset before training on a large one.
Error analysis and performance auditing
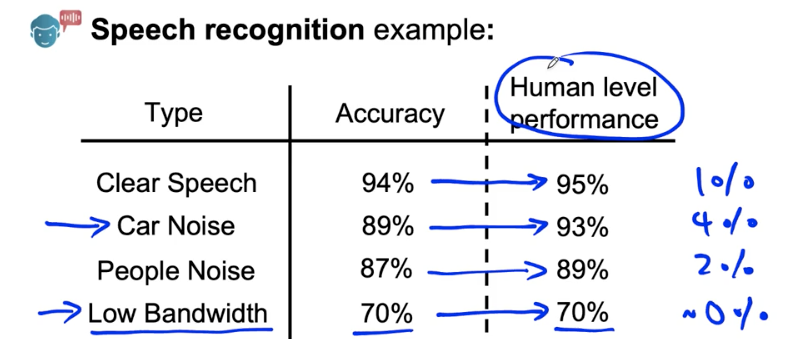
Error analysis example
Speech recognition example

Iterative process of error analysis
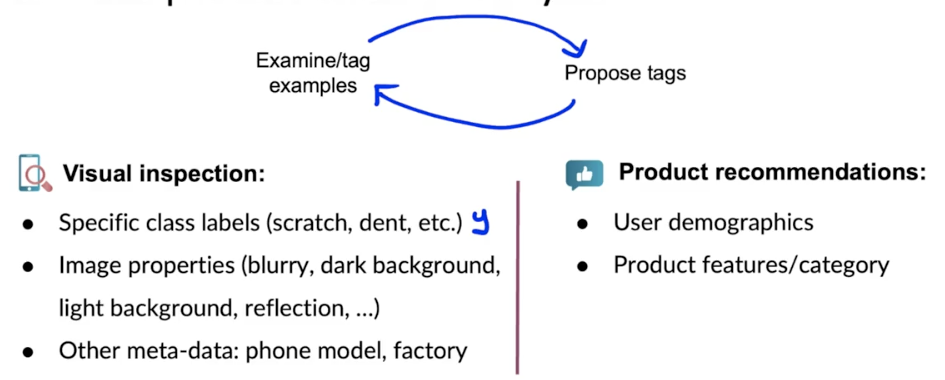
Useful metrics for each tag
- What fraction of errors has that tag?
- Of all data with that tag, what fraction is misclassified?
- What fraction of all the data has that tag?
- How much room for improvement is there on data with that tag?
Prioritizing what to work on
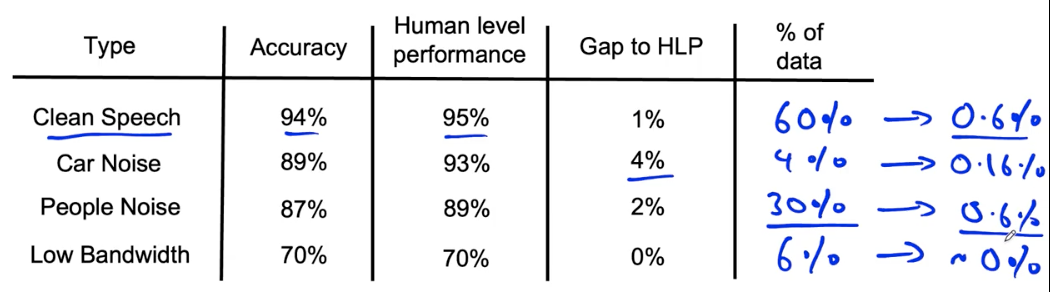
Decide on most important categories to work on based on:
- How much room for improvement there is
- How frequently that category appears
- How easy is to improve accuracy in that category
- How important it is to improve in that category
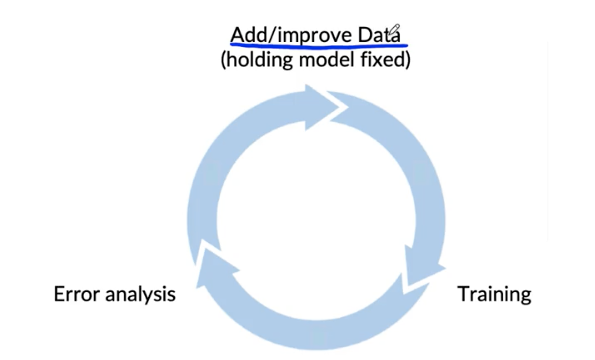
Adding/improving data for specific categories
For categories you want to prioritize:
- Collect more data
- Use data augmentation to get more data
- Improve label accuracy/data quality
Skewed datasets
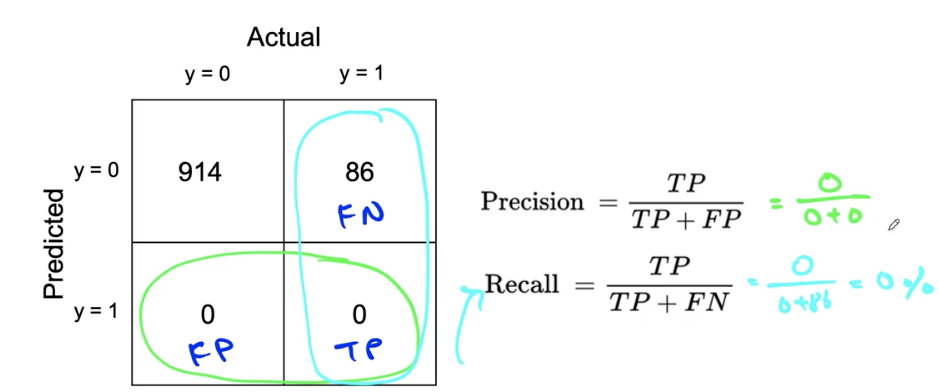
Confusion matrix: Precision and Recall
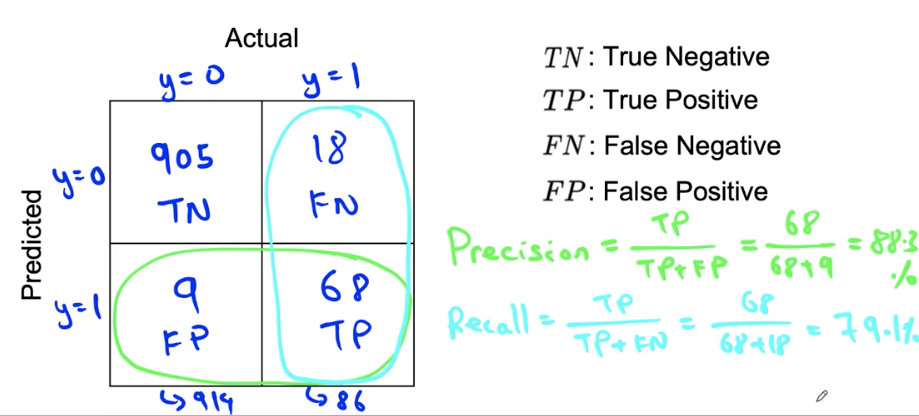
What happens with print(‘0’)?
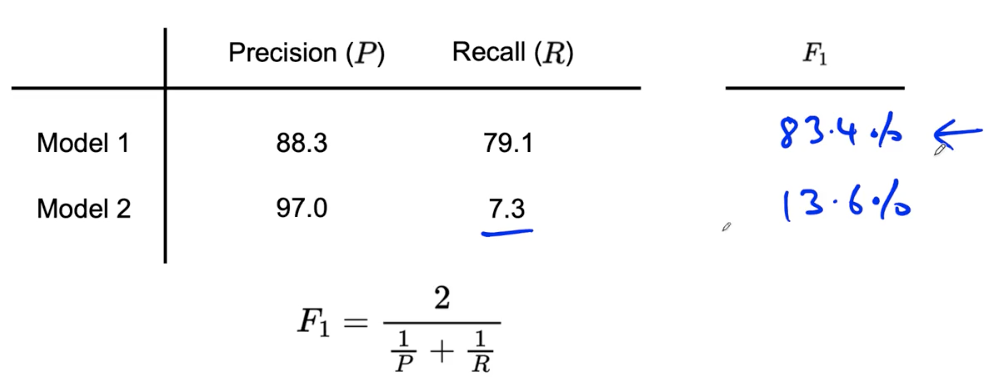
Combining precision and recall — F1 score
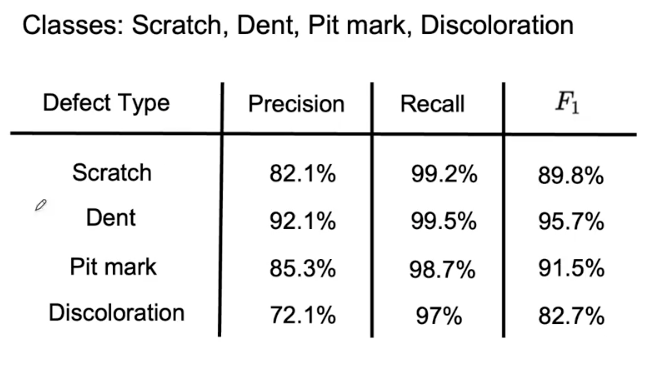
Multi-class metrics
Performance auditing
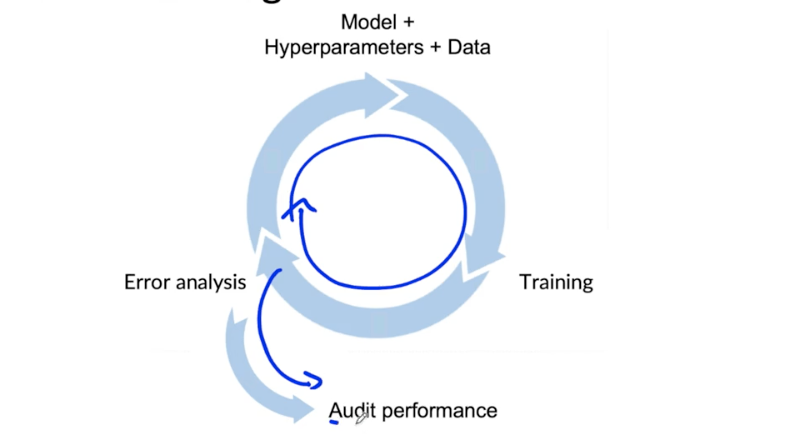
Auditing framework
Check for accuracy, fairness/bias, and other problems.
- Brainstorm the ways the system might go wrong.
- Performance on subsets of data (e.g., ethnicity, gender).
- How common are certain errors (e.g., FP, FN).
- Performance on rare classes.
- Establish metrics to assess performance against these issues on appropriate slices of data.
- Get business/product owner buy-in.
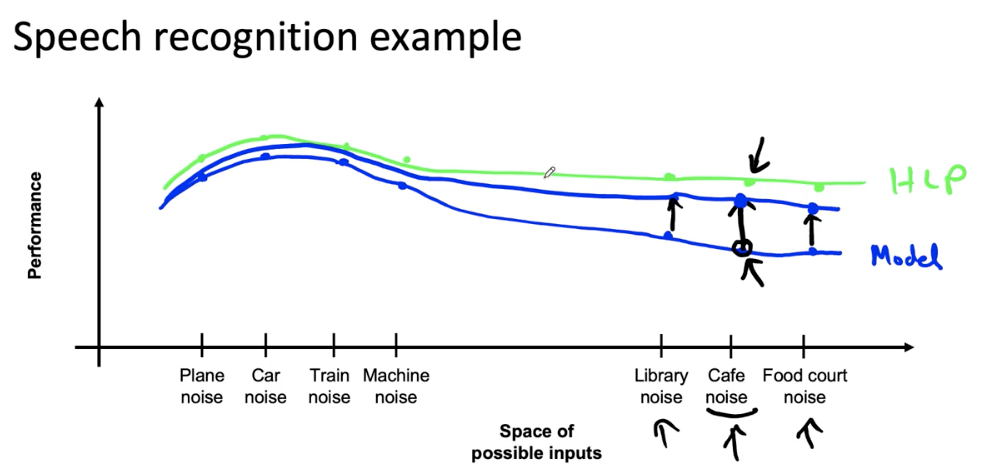
Speech recognition example
- Brainstorm the ways the system might go wrong.
- Accuracy on different genders and ethnicities.
- Accuracy on different devices.
- Prevalence of rude mis-transcriptions.
- Establish metrics to assess performance against these issues on appropriate slices of data.
- Mean accuracy for different genders and major accents.
- Mean accuracy on different devices.
- Check for prevalence of offensive words in the output.
Data iteration
Data-centric AI development
- Model-centric view: take the data you have, and develop a model that does as well as possible on it.
- Hold the data fixed and iteratively improve the code/model.
- Data-centric view: the quality of the data is paramount. Use tools to improve the data quality; this will allow multiple models to do well.
- Hold the code fixed and iteratively improve the data.
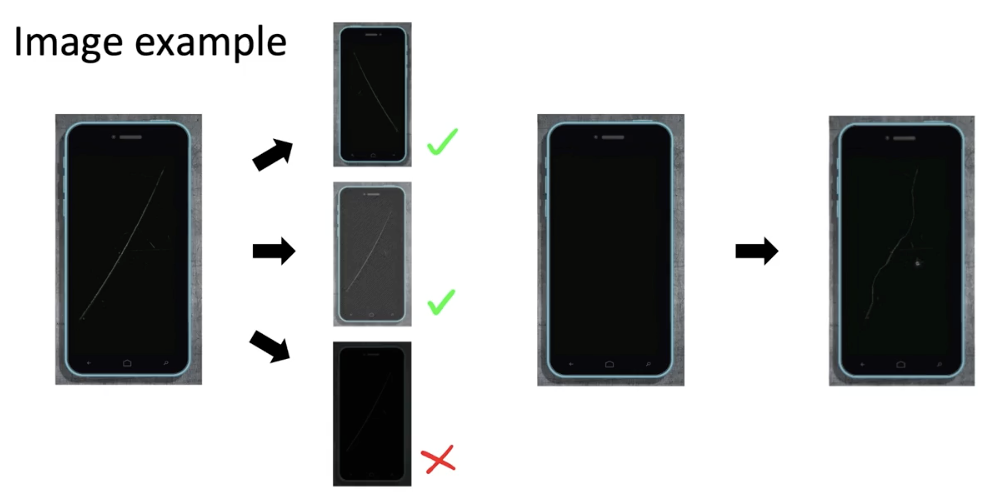
A useful picture of data augmentation
Data augmentation
Goal:
- Create realistic examples that (i) the algorithm does poorly on, but (ii) humans (or other baseline) do well on
Checklist:
- Does it sound realistic?
- Is the x→ y mapping clear? (e.g. can humans recognize speech?)
- Is the algorithm currently doing poorly on it?
Data iteration loop
Can adding data hurt performance?
For unstructured data problems, if:
- The model is large (low bias).
- The mapping x→y is clear (e.g., given only the input x, humans can make accurate predictions).
Then, adding data rarely hurts accuracy.

Adding features to structured data
Restaurant recommendation example:
- Vegan are frequently recommended restaurants with only meat options.
- Possible features to add?
- Is person vegan (based on past orders)?
- Does restaurant have vegan options (based on menu)?
Other food delivery examples
- Only tea/coffee and only pizza
- What are the added features that can help make a decision?
- Product recommendation:
Collaborative filtering ——> Content based filtering (cold-start)
Data iteration
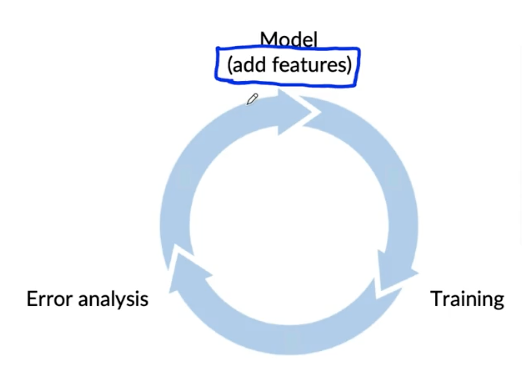
- Error analysis can be harder if there is not good baseline (such as HLP) to compare to.
- Error analysis, user feedback and benchmarking to competitors can all provide inspiration for features to add.
Experiment tracking
- What to track?
- Algorithm/code versioning
- Dataset used
- Hyperparameters
- Results
- Tracking tools
- Text files
- spreadsheet
- Experiment tracking system
- Desirable features
- Information needed to replicate results
- Experiment results, ideally with summary metrics/analysis
- Perhaps also: resource monitoring, visualization, model error analysis
From big data to good data
Try to ensure consistently high-quality data in all phases of the ML project lifecycly
Good data:
- Covers important cases (good coverage of inputs x)
- Is defined consistently (definition of labels y is unambiguous)
- Has timely feedback from production data (distribution covers data drift and concept drift)
- Is sized appropriately
Code Link : Google Colab
Reading Material Week 2:
Week 3: Data Definition and Baseline
Define Data and Establish Baseline
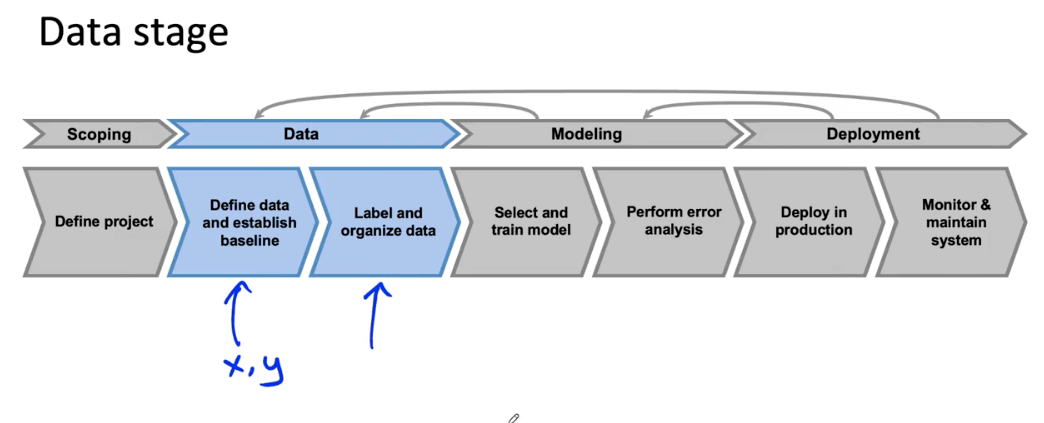
Data definition questions
- What is the input x?
- lightning? contrast? resolution?
- What features need to be in included?
- What is the target label y?
- How can we ensure labelers give consistent labels?
Major types of data problems
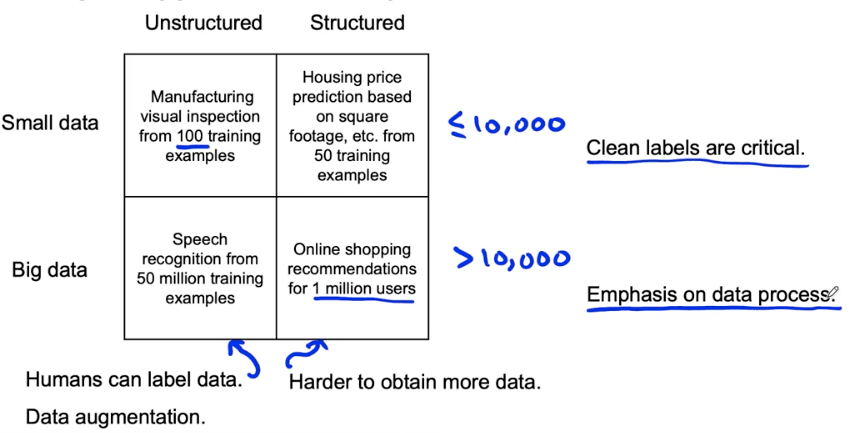
Unstructured vs. structured data
- Unstructured data
- may or may not have huge collection of unlabeled examples x.
- Humans can label more data.
- Data augmentation more likely to be helpful.
- Structured data
- May be more difficult to obtain more data.
- Human labelling may not be possible (with some exceptions)
Small data vs. big data
- Small data
- Clean labels are critical
- Can manually look through dataset and fix labels
- Can get all the labelers to talk to each other
- Big data
- Emphasis data process
Why label consistency is important?
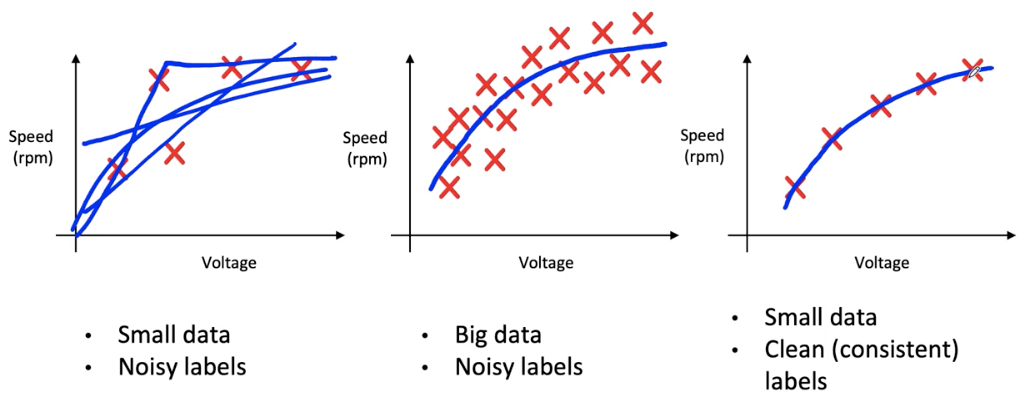
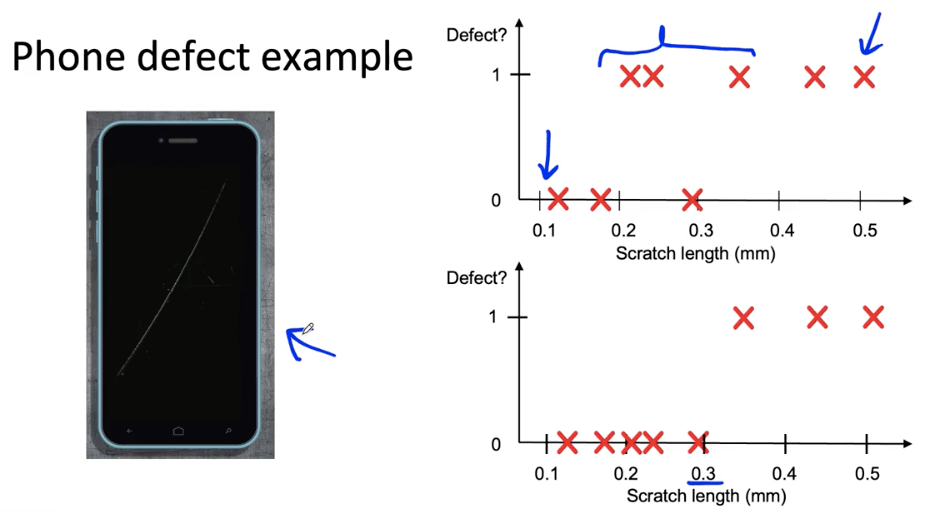
Big data problems can have small data challenges too
Problems with a large dataset but where there’s a long tail or rare events in the input will have small data challenges too.
- Web search
- Self-driving cars
- Product recommendation systems
Improving label consistency
- Have multiple labelers label same example.
- When there is disagreement, have MLE, subject matter expert (SME) and/or labelers discuss definition of y to reach agreement.
- If labelers believe that x doesn’t contain enough information, consider changing x.
- Iterate until it is hard to significantly increase agreement
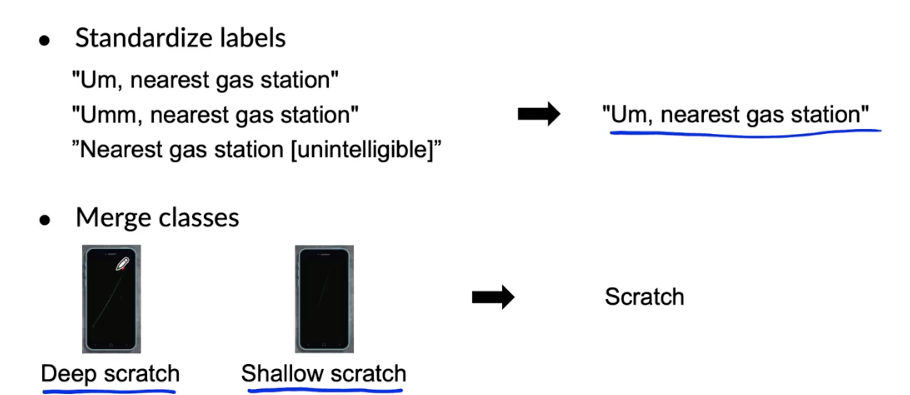
Have a class/label to capture uncertainty

Small data vs. big data (unstructured data)
- Small data
- Usually small number of labelers
- Can ask labelers to discuss specific labels
- Big data
- Get to consistent definition with a small group.
- Then send labeling instructions to labelers.
- Can consider having multiple labelers label every example and using voting or consensus labels to increase accuracy.
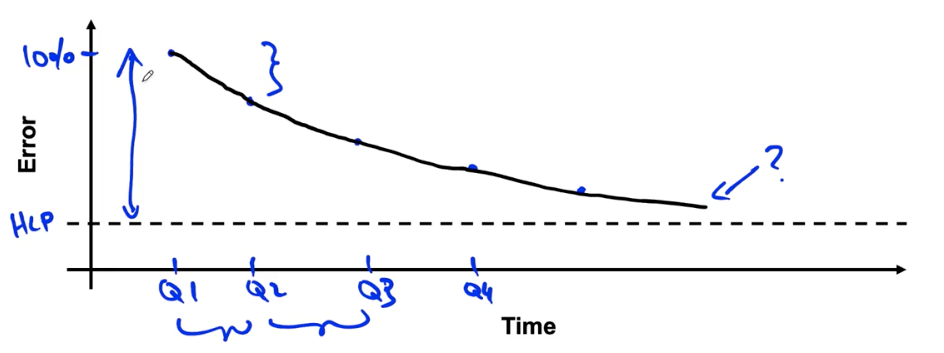
Why measure HLP?
Estimate Bayes error / irreducible error to help with error analysis and prioritization.

Other uses of HLP
- In academia, establish and beat a respectable benchmark to support publication.
- Business or product owner asks for 99% accuracy. HLP helps establish a more reasonable target.
- “Prove” the ML system is superior to humans doing the job and thus the business or product owner should adopt it. (Use with caution)
The problem with beating HLP as a ‘proof’ or ML ‘superiority’

Raising HLP
When the ground truth label is externally defined, HLP gives an estimate for Bayes error / irreducible error.
But often ground truth is just anther human label.
- When the label y comes from a human label, HLP « 100% may indicate ambiguous labeling instructions.
- Improving label consistency will raise HLP
- This makes it harder for ML to beat HLP. But the more consistent labels will raise ML performance, which is ultimately likely to benefit the actual application performance.
HLP on structured data
Structured data problems are less likely to involve human labelers, thus HLP is less frequently used.
Some exceptions:
- User ID merging: same person?
- Based on network traffic, is the computer hacked?
- Is the transaction fraudulent?
- Spam account? Bot?
- From GPS, what is the mode transportation - on foot, bike, car, bus?
Label and Organize Data
How long should you spend obtaining data?
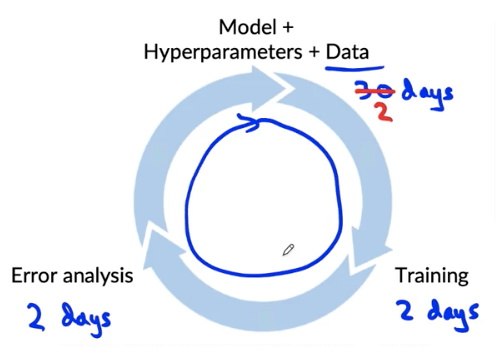
- Get into this iteration loop as quickly as possible.
- Instead of asking: how long it would take to obtain m examples? ask: How much data can we obtain in k days.
- Exception: if you have worked on the problem before and from experience you know you need m examples.
Inventory data
Brainstorm list of data sources
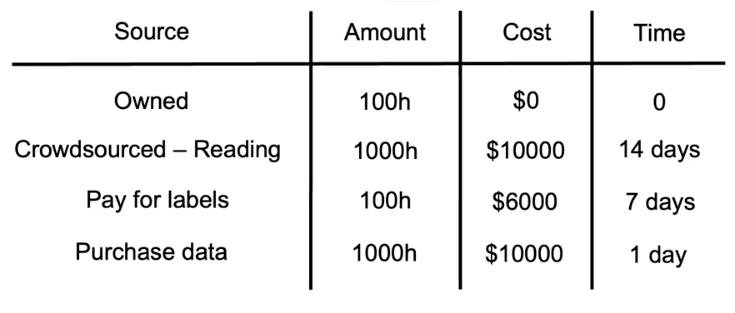
Other factors: data quality, privacy, regulatory constrains
Labeling data
- Options: in-house vs. outsourced vs. crowdsourced
- Having MLEs label data expensive. But doing this for just a few days is usually fine
- Who is qualified to label?
- Speech recognition - any reasonable fluent speaker
- Factory inspection, medical image diagnosis - SME (subject matter expert)
- Recommender systems - maybe impossible to label well
- Don’t increase data by more than 10x at a time
Data pipeline example
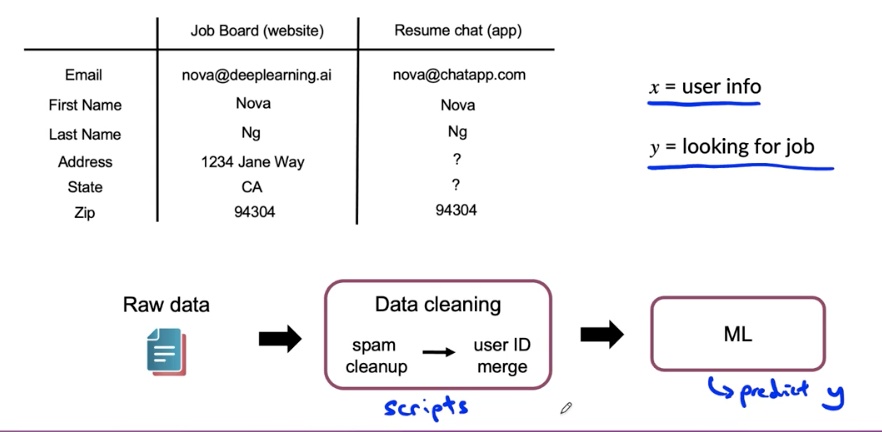
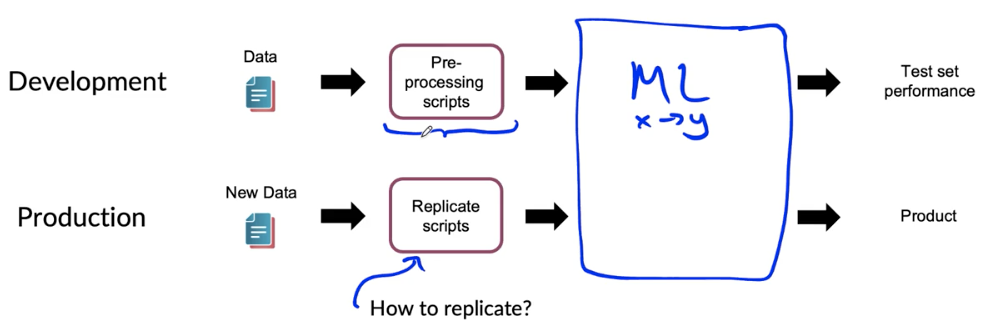
POC and Production phases
- POC(proof-of-concept):
- Goal is to decide if the application is workable and worth deploying.
- Focus on getting the prototype to work
- It’s ok if data pre-processing is manual. But take extensive notes/comments
- Production phase:
- After project utility is established, use more sophisticated tools to make sure the data pipeline is replicable.
- E.g., Tensor Flow Transform, Apache Beam, Airflow, …
Data pipeline example
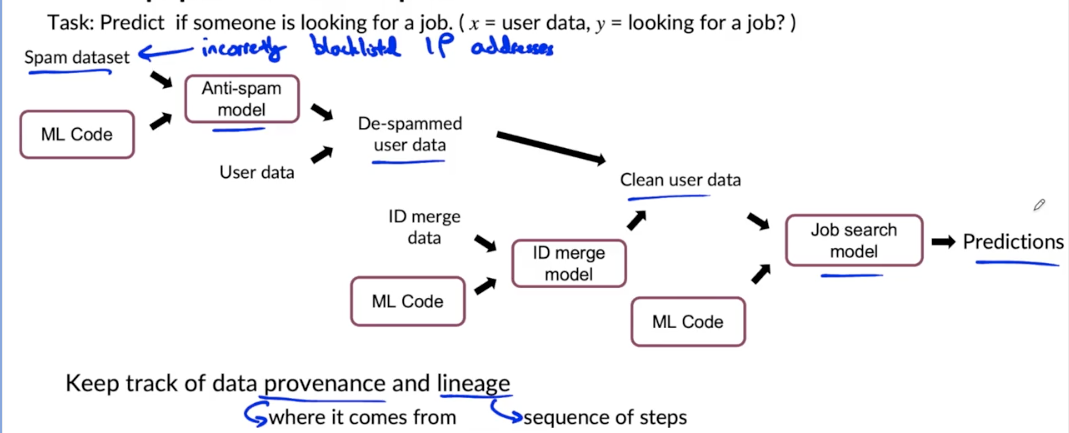
Meta-data
- Examples:
- Manufacturing visual inspection: time, factory, line #, camera settings, phone model, inspector ID,…
- Speech recognition: device type, labeler ID, VAD model ID,…
- Useful for:
- Error analysis. Spotting unexpected effects.
- Keeping track of data provenance.
Balanced train/dev/test/ splits in small data problems
Visual inspection example: 100 examples, 30 positive (defective)
- Train/dev/test: 60%/20%/20%
- Random split: positive example: 21/2/7 (35%/10%/35%)→ dev set is not representative
- Want: 18/6/6 (30%/30%/30%) →balanced split
- No need to worry about this with large datasets - a random split will be representative
Scooping
What is scoping?
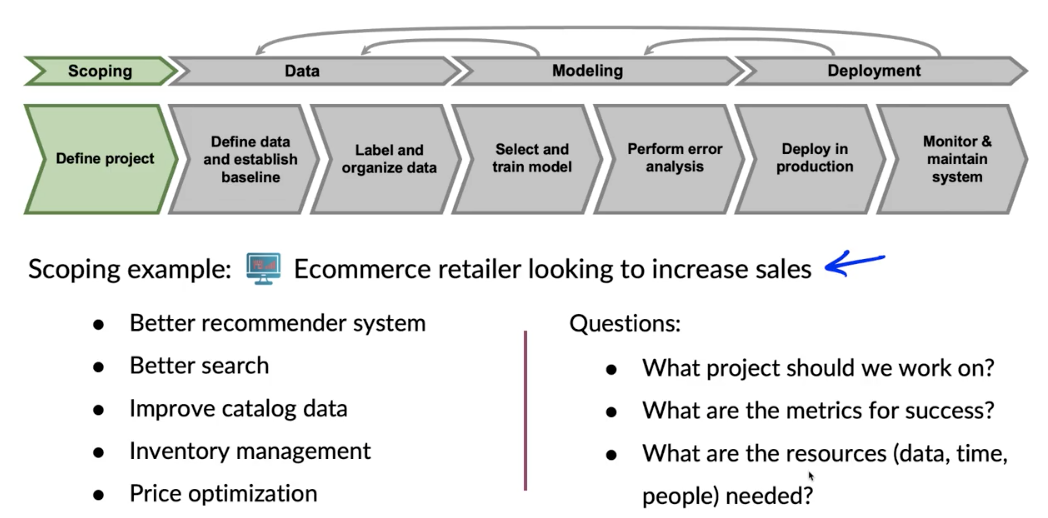
Scoping process
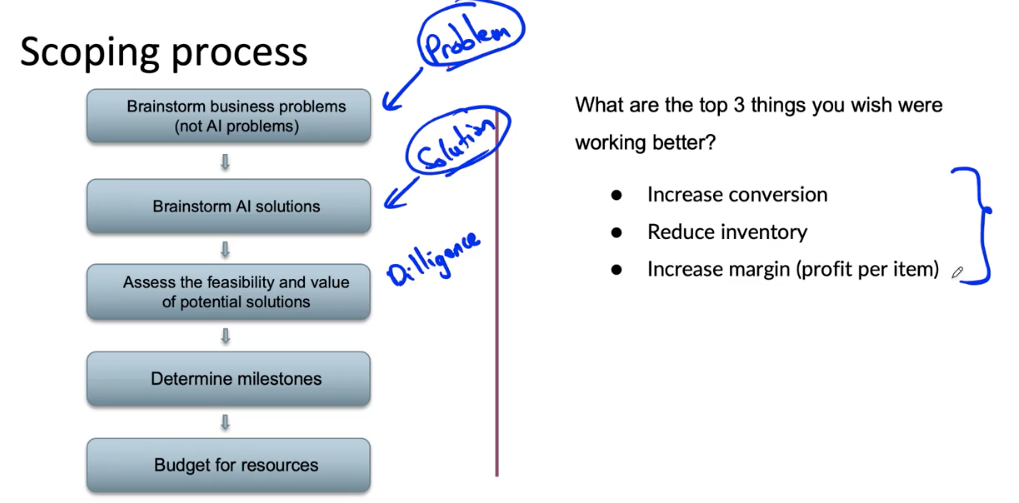
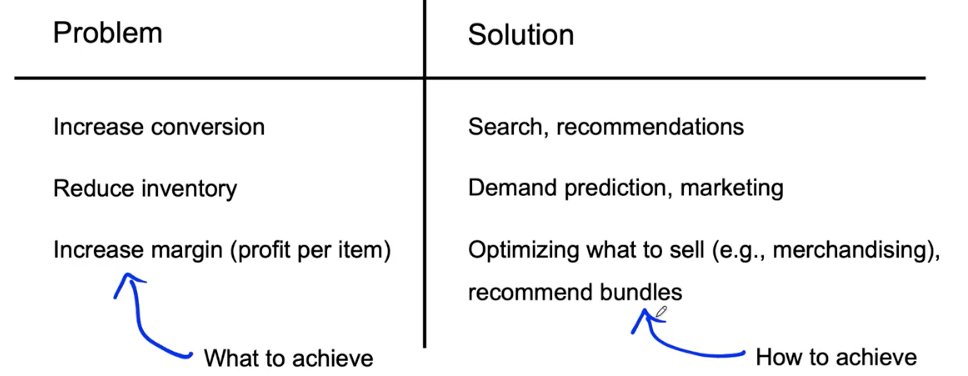
Separating problem identification from
Feasibility: Is this project technically feasible?
- Use external benchmark (literature, other company, competitor)
Why use HLP to benchmark?
People are very good on unstructured data tasks
Criteria: can a human, given the same data, perform the task?
Do we have features that are predictive?
- Given past purchases, predict future purchases ✅
- Given weather, predict shopping mall foot traffic ✅
- Given DNA info, predict heart disease ❓
- Given social media chatter, predict demand for a clothing style ❓
- Given history of stock’s price, predict future price of that stock ❌
History of project
Diligence on value

Ethical considerations
- Is this project creating net positive societal value?
- Is this project reasonable fair and free from bias?
- Have any ethical concerns been openly aired and debated?
Milestones & Resourcing
Key specifications:
- ML metrics (accuracy, precision/recall, etc.)
- Software metrics (latency, throughput, etc. given compute resources)
- Business metrics (revenue, etc.)
- Resources needed (data, personnel, help from other teams)
- Timeline
If unsure, consider benchmarking to other projects, or building a POC (Proof of Concept) first.
Colab: https://www.coursera.org/learn/introduction-to-machine-learning-in-production/ungradedLab/hnDmK/data-labeling/lab
Reading Material Week 3:
https://arxiv.org/pdf/1706.06969.pdf
Overall resources:
Konstantinos, Katsiapis, Karmarkar, A., Altay, A., Zaks, A., Polyzotis, N., … Li, Z. (2020). Towards ML Engineering: A brief history of TensorFlow Extended (TFX). http://arxiv.org/abs/2010.02013
Paleyes, A., Urma, R.-G., & Lawrence, N. D. (2020). Challenges in deploying machine learning: A survey of case studies. http://arxiv.org/abs/2011.09926