Building API for Predicting Mando-pop Popularity
Authors: Yufei Zhao, Peeta Li
1. Overview: The problem and solution
The Problem
- Automatic composition models are commonly used for Mando-pop music productions, and thus requires a way to identify potential trending songs from a batch of auto-produced songs. This can be accomplished by so called hit song prediction model.
- We review 10+ papers on hit song prediction models through literature search. Although various models can be found through Googling, these models usually have two limitations: i) Such models were trained mostly with western music, such as English, French, Spanish songs, leaving its use on Mando-pop questionable and ii) Such models are usually presented in a paper or conference abstract, with little sharing codes via Github repository, and no model has been fully wrapped up for easy implement.
The Solution
- We adopted the structures of an inception convolutional neural network (CNN) hit song prediction model that takes audio features (i.e., Mel Spectrogram) as input for popularity prediction. More of the model details can be found here. We then trained our model with all Mando-pop songs scrapped from the preview MP3 URL obtained with Spotify API. For the implementation of our trained model, we developed a REST API using FLASK to make our model easily accessible (as shown below). Our trained model can be found here and our API can be accessed here.
- We accomplished this through the pipeline shown below. We will debrief each step of the pipeline in sections down below.
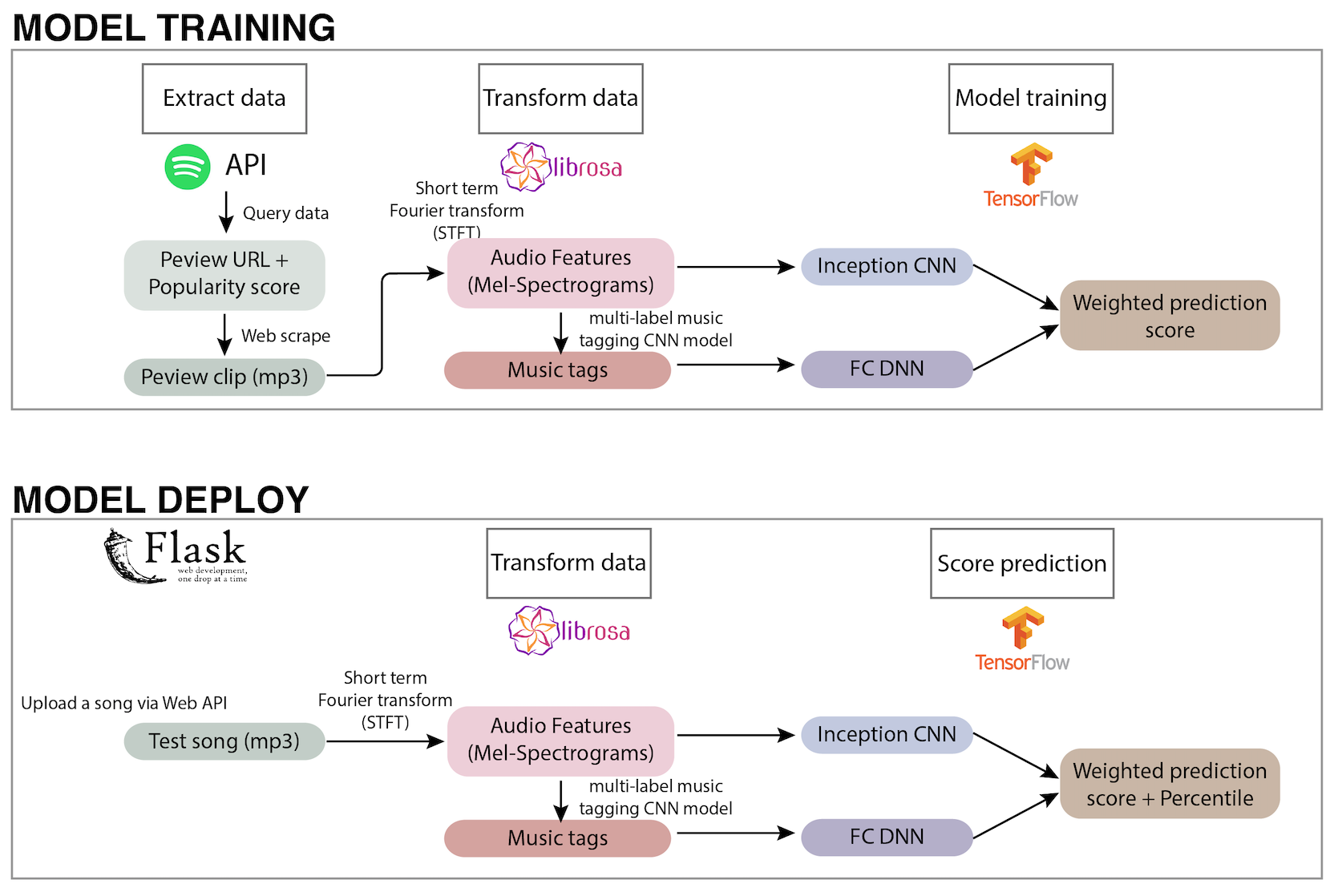 ## 2. Get-ready: explore data, benchmark baseline model
## 2. Get-ready: explore data, benchmark baseline modelQuery data with Spotify API
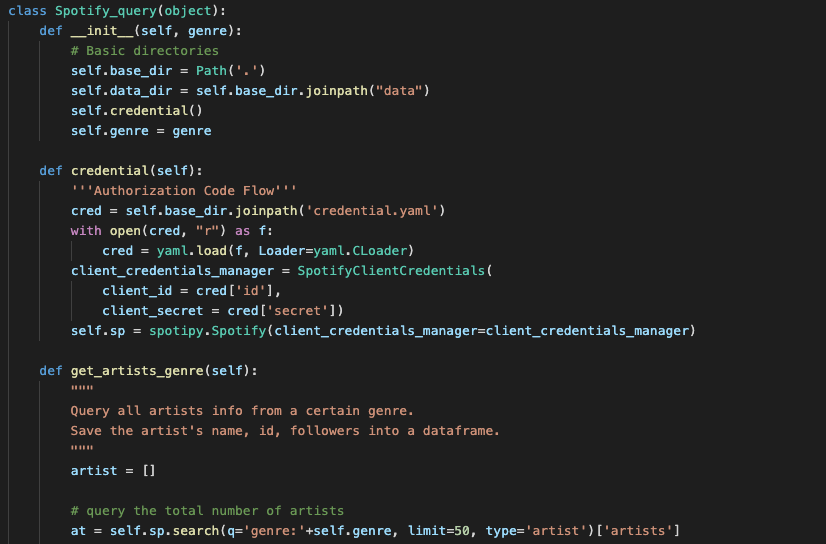
We wrote a class to extract all 90212 Mandopop songs, after removing duplicates, and their related information. We accomplished this by:
querying all the artists within “mandopo” genre
querying all the albums of each artist
querying all the songs within each album,
removing duplicate based on same preview URL (which means the same song).
For each song, we collected its URL (for downloading the preview song clip), Spotify-provided audio features (e.g., danceability, loudness), and its popularity score. The popularity score of a song is a value between 0 and 100, with 100 being the most popular. The popularity is calculated by algorithm and is based, in the most part, on the total number of plays the track has had and how recent those plays are.
Benchmark baseline model & Diagnostic for bias and variance
- We built a baseline linear models using the Spotify-provided audio features (e.g., danceability, loudness) for hit song prediction (popularity score) with two aims. First, we want to test the feasibility of using audio features to predict popularity. Second, we want to benchmark the baseline model performance so that we could evaluate our more sophisticated model later on.
- With a cross-validation framework, the averaged MSE for validation folds were around 89, and the predictive accuracy, as measured by Spearman correlation coefficient between actual and predicted popularity scores reached 0.27.
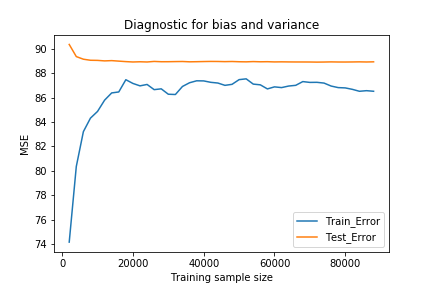
- We did a quick diagnostic of the error, which in principle consists 1) Bias, 2) Variance, and 3) irreducible error. As shown in the figure below, test error does not drop as training sample size increases, and test error is already very close to training error, suggesting that the baseline model is under-fitting and has high bias. Thus a direct solution is to increases the number of audio features. Of course, this goes beyond what Spotify-available features, and we used audio data preprocessing to quantify our predictive audio features, as shown in the next section.
3. The predictive model
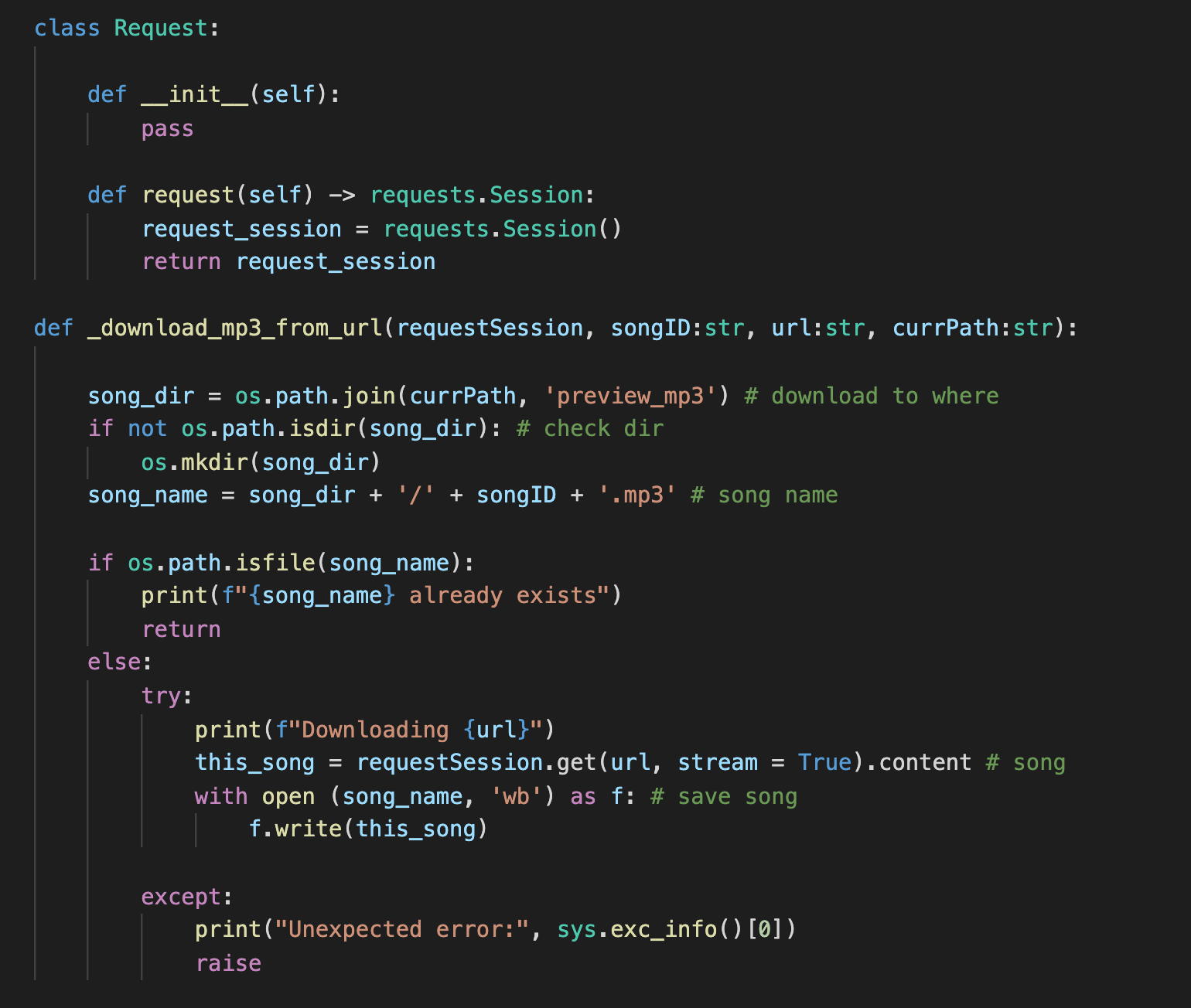
Web-scrap data
- Using the preview-URLs queried using Spotify API, we web-scraped the preview-mp3 (~30s long) from those URLs.
Extract mel spectrogram
- Mel (Melody) spectrograms contains information across three aspects. First, using STFT (Short-Time Fourier Transform), mel-spectrogram has time-frequency representation. Second, it represents amplitude in a perceptually-relevant manner by amplitude-db conversion. Most importantly, it represents frequency also in a perceptually-relevant manner by converting frequency to the mel scale. Thus, the mel-spectrogram includes ample perceptually relevant audio features for our deep learning mode.
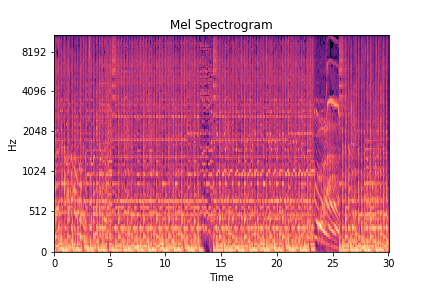
Obtain music tag
- Using a pre-trained CNN model described here. We computed the music tag loading for each mp3 clips. These music tag loadings will be part of the input to our final model, along with the mel spectrogram.
- Below are the structure of this auto-tagging CNN and a sample result for a mp3 clip’s tag loadings.
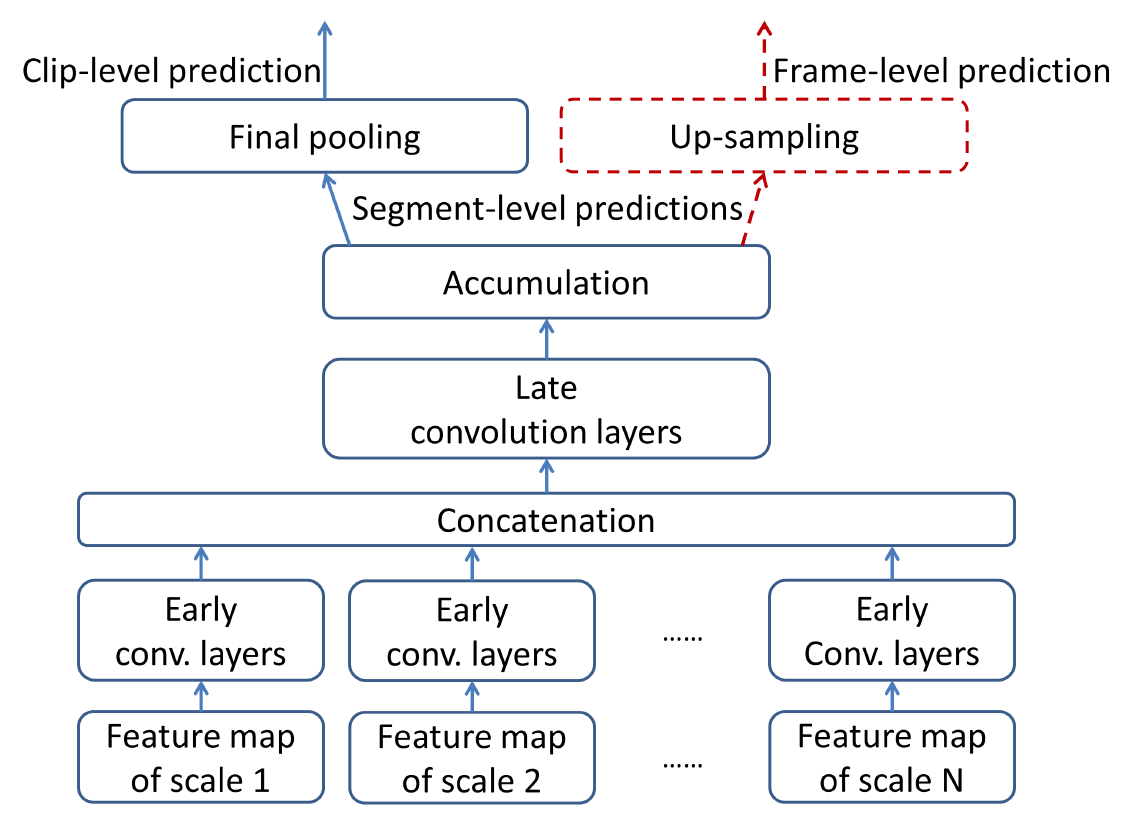
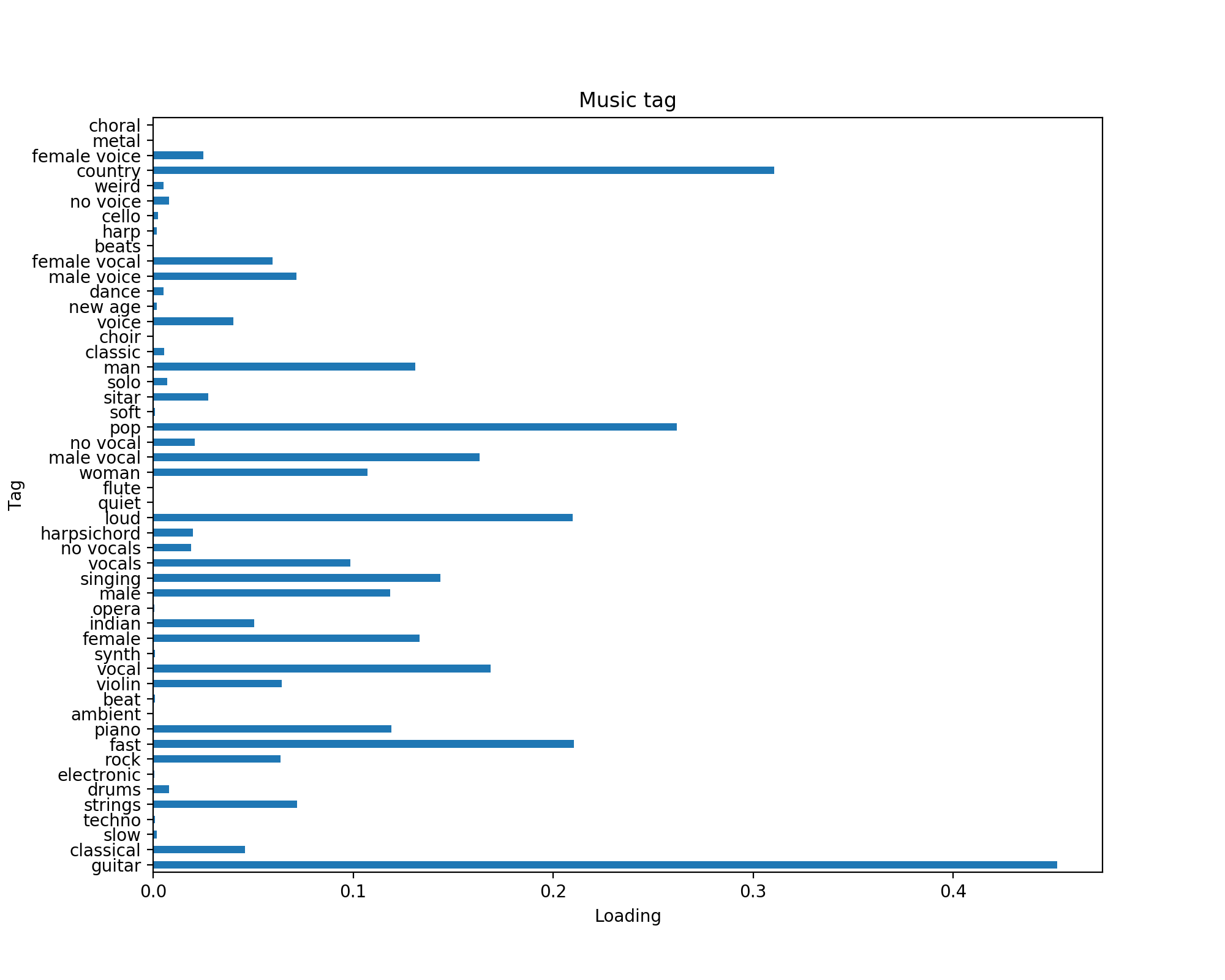
Model training and testing
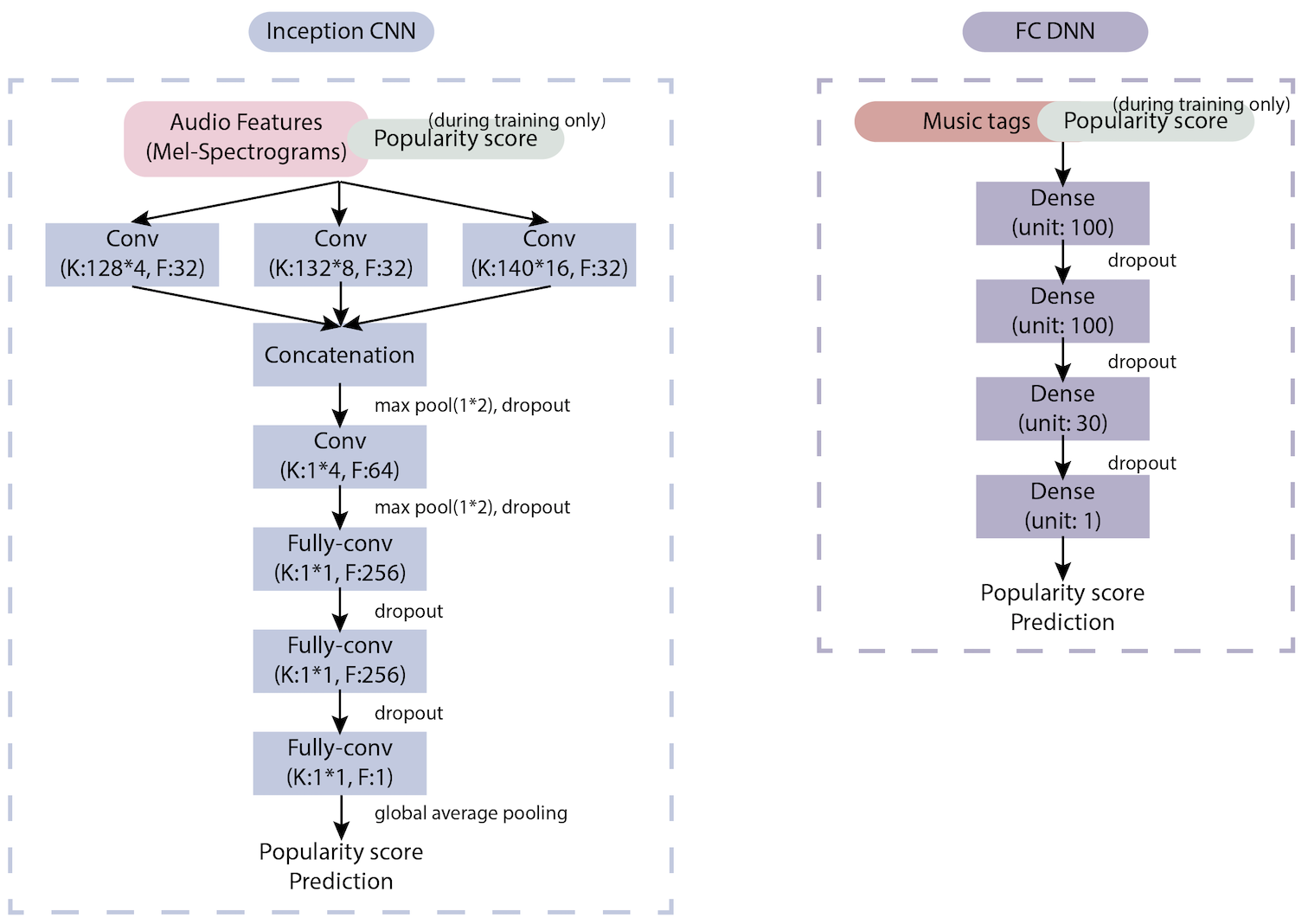
- We reviewed 10+ papers on hit song prediction models. We chose an inception CNN since its has the highest predict accuracy among all models and it can use the popularity score we extracted from Spotify API for prediction. The structure of the model can be seen below. The model outputs a prediction score of popularity.
- The mel-spectrogram features of the mp3 clip can only capture the low level information of a song. Thus, we want to incorporate the higher level information, tag loadings, to improve the performance. To do this, we passed the tag loadings for each song through a fully-connected DNN and yield another prediction score of popularity.
- We took a weighted averaged of the two prediction score and yielded the final popularity prediction score.
- We trained the model for 10 epochs before the validation loss started to increase.
Model performance
- With more abundant audio features, we decreased the MSE from the baseline MSE = 89 now to MSE = 82. Likewise, we improved the model predictive accuracy, as measured by Spearman correlation coefficient from 0.27 to 0.34.
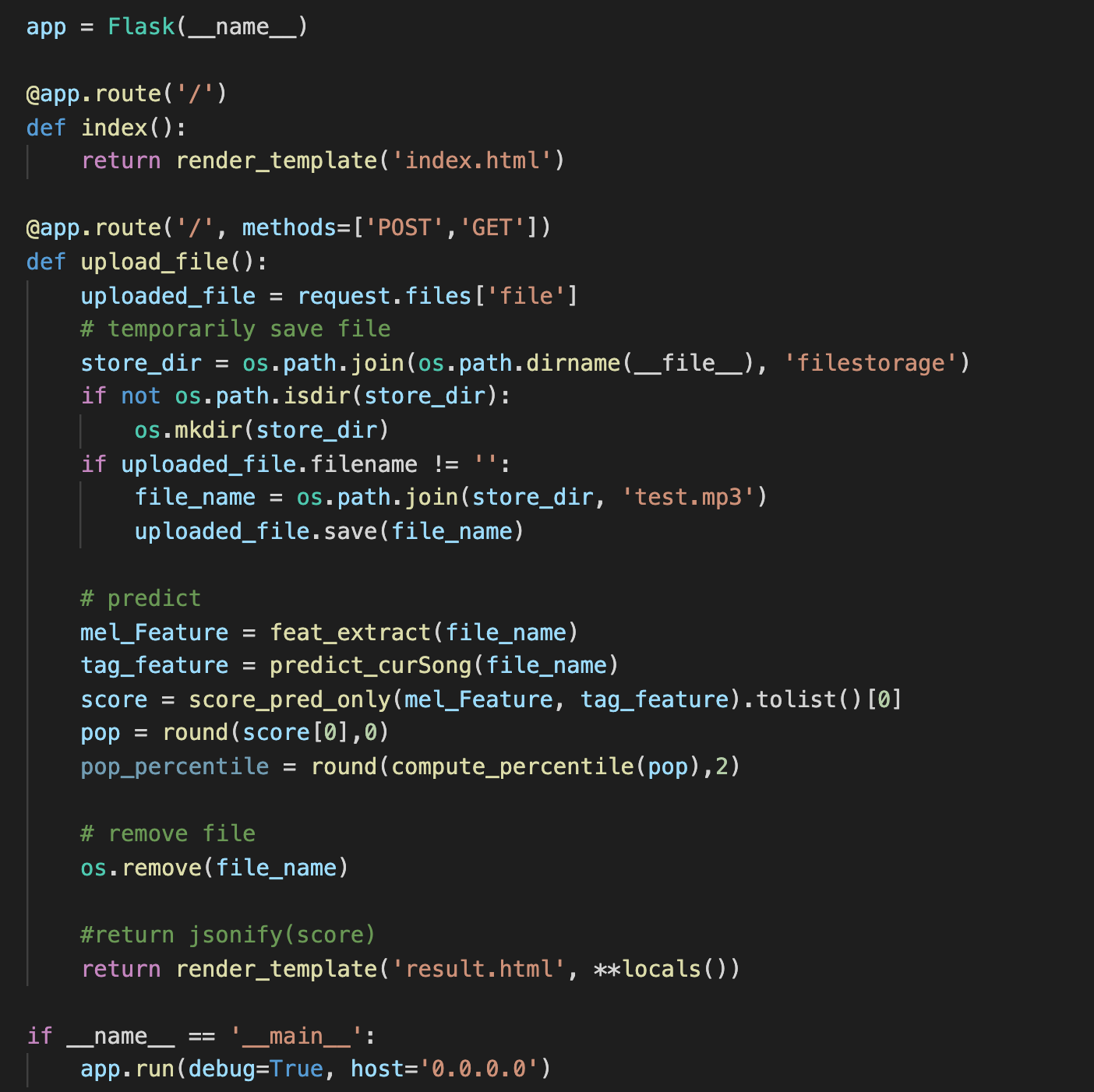
4. Develop API
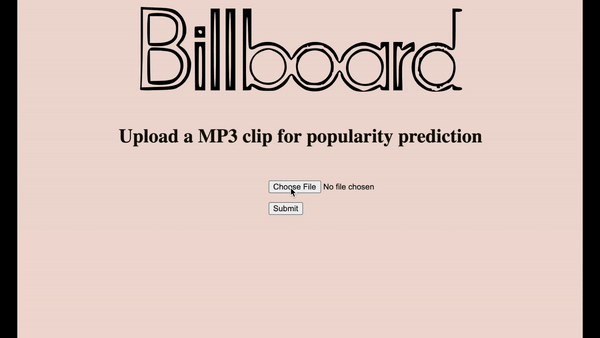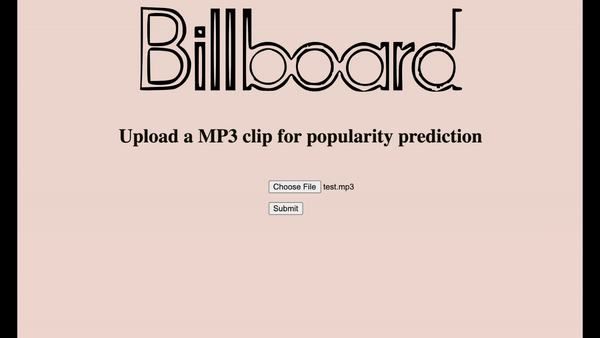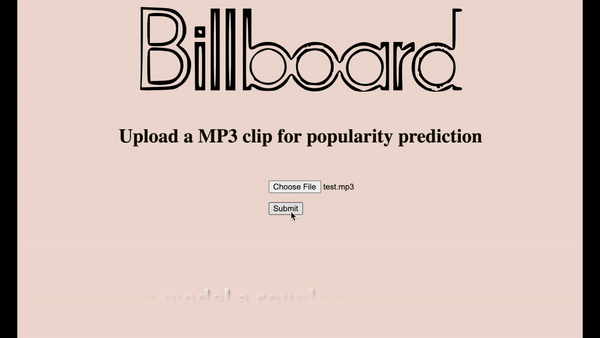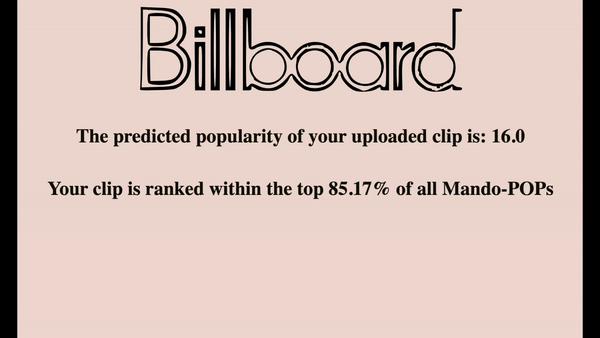
- We wrapped up our model and developed a REST API using FLASK, which yields the gif demo presented at the start of this post.
- After loading the mp3 clip, our API will produce two estimated scores: 1) the predicted Spotify popularity score, 2) the percentile of popularity among all Mando-pop songs on Spotify.
- The detail usage of the API and the codes can be found here.
Reference
[1] Yu, L. C., Yang, Y. H., Hung, Y. N., & Chen, Y. A. (2017). Hit song prediction for pop music by siamese cnn with ranking loss. arXiv preprint arXiv:1710.10814. repo
[2] Liu, J. Y., & Yang, Y. H. (2016, October). Event localization in music auto-tagging. In Proceedings of the 24th ACM international conference on Multimedia (pp. 1048-1057).